Building autonomous systems often feels like starting from zero every time a model hits a roadblock. A new technical paper suggests a shift toward collective skill evolution: allowing AI agents to share their successes so they stop repeating the same mistakes. Developers can find details in the SkillClaw arXiv preprint regarding a framework where agent skills update across users, turning messy real sessions into reusable improvements for agentic workflow optimization.
Modern autonomous systems function as software systems that plan steps and use tools to reach complex goals. These agents browse websites, write code, and produce structured outputs that slot into everyday autonomous workflows.
Most of these systems still rely on frozen skill definitions that rarely change after launch. This lack of flexibility means that when an agent hits a broken login page or an error loop, it usually stops until a person steps in to help. SkillClaw aims to bridge this gap by making failures the catalyst for shared growth.
Shared wisdom gathered from thousands of user sessions creates a signal that improves the entire repository at once. Instead of one agent learning in isolation, a single team’s successful workaround can quickly transform into a standardized update that benefits every user in the network. The project’s high visibility on the Hugging Face Daily Papers ranking reflects growing momentum among developers who prioritize sustainable automation over surface-level demos.

SkillClaw System Overview: Core Definitions for Collective Skill Evolution
Key Facts About AI Agent Reliability and Shared Skill Updates
Understanding how these systems work requires looking past the industry hype to see the actual mechanics underneath. The technical report breaks down exactly how the system behaves without relying on abstract claims:
- SkillClaw’s core idea is a shared loop that updates agent skills based on real sessions.
- Common breakdown patterns are turned into reliable playbooks to stop the frustration of repeated tool failures.
- Detailed instructions on how skills sync through shared storage describe the client proxy and evolve server setup without forcing users to start from scratch.
- Evaluation claims point to tougher, tool-based benchmarks where real-work conditions are tested through the WildClawBench task catalog.
Collaborative systems inevitably raise a practical question: who reviews the updates, and how do teams prevent a clever shortcut from becoming a fragile standard?

The SkillClaw Framework: Transforming Sessions into Reusable Playbooks
Managing Agentic Workflows with Reusable Instruction Playbooks
SkillClaw is built on a practical claim: agent skills should not remain frozen after launch. Think of an agent skill as a practical set of instructions that guides a task from start to finish, much like a folder of rules within the OpenClaw framework.
Solving Operational Failures and Brittle Static Skill Definitions
SkillClaw treats real interaction logs as learning material. When users hit failures, edge cases, or slow detours, those traces become data an evolver can analyze to refine the skill definition itself.
Shifting toward a shared update loop matters because the most frustrating agent failures are rarely philosophical; they are operational. Common issues like login flow changes, download prompts, or tool error codes often cause agents to repeat the same mistakes indefinitely.
Building a Shared Repository through Collective Evolution Loops
Repetitive failures in day-to-day automation often stem from minor upstream changes. A small team might encounter the same weekly report error without a way to standardize the fix.
- Without a shared loop, workarounds remain trapped in private notes or temporary prompts.
- With a collective system, the improved sequence is absorbed into a shared skill repository.
- Subsequent runs automatically benefit from the update as if the system learned from experience.
Integrating these successful sequences ensures that teams stop rediscovering the same manual fixes.
Engineering Reliability and Safety into AI Agent Infrastructure
This systems-first framing lines up with a broader pattern in coding agents, where permission logic, containment, and recovery rules often matter as much as the model itself. Architecture patterns utilizing a deny-first permission model illustrate why smarter output and safer execution remain separate engineering problems in coding agents.
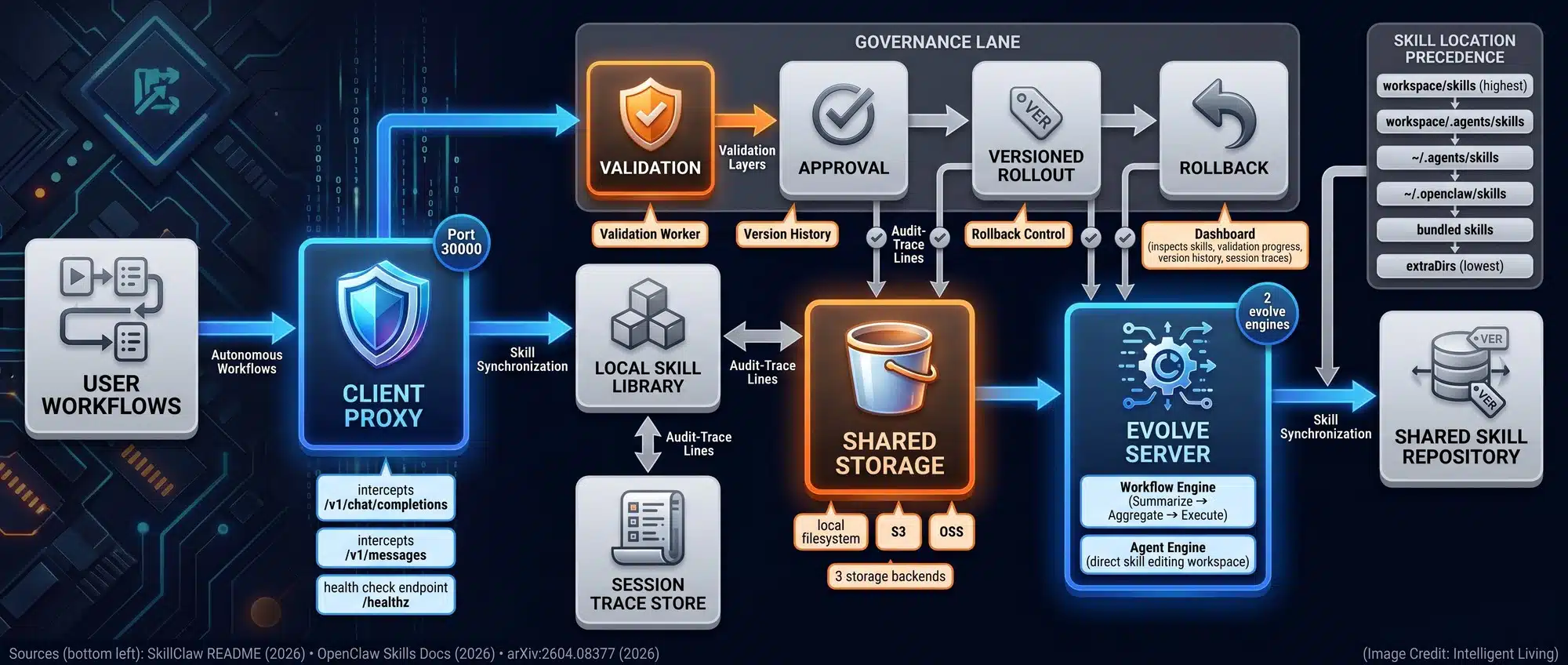
Technical Architecture of SkillClaw: From Client Proxy to Evolve Server
Fragmented user data becomes a structured feedback cycle that stops session history from being thrown away. The goal is simple: fewer repeated failures, faster recovery, and skills that improve across users rather than staying trapped inside one person’s prompt history.
Two primary components in the project’s SkillClaw open-source repository drive the framework: a client proxy to capture data and an evolve server to refine skill definitions.
Capturing Interaction Traces with the SkillClaw Client Proxy
By acting as a switchboard, the proxy maps every tool call and failure point to build a complete record of what happened. For teams running coding assistants or automated operational checklists, that proxy can gather structured traces quietly in the background. Over time, those traces add up to something more useful than a pile of chat transcripts. They become a record of what actually broke in real workflows.
Synchronizing Shared Storage and Skill Optimization via Evolve Servers
A flexible setup lets users start small with just a proxy, while larger teams can scale up to shared storage and review gates to ensure skills are safe before they spread. Automating the feedback loop ensures that repeated missteps in browser tasks are distilled into cleaner instruction sequences, benefiting subsequent users without requiring technical background knowledge.

AI Agent Governance: Validation Layers and WildClawBench Testing
Safety Protocols for Preventing Error Contamination in Shared Skills
Version Control and Automated Validation Prior to Skill Distribution
Spreading system improvements also carries the risk of spreading errors. SkillClaw mitigates this through a combination of oversight tools and version control.
- Optional validation workers inspect new skills for potential conflicts.
- A centralized dashboard tracks skill versions alongside session traces to ensure updates are tied to evidence.
- Updates are tied directly to evidence for comparison against previous iterations.
- One-click rollbacks allow teams to revert skills if regressions are detected.
These governance layers ensure that collective learning does not come at the expense of system stability.
Sandboxed Execution and Multi-Layer Approval for Risk Mitigation
Consider a workflow where an agent learns a shortcut that skips a verification step because it worked once. Without review gates, that shortcut can cascade across a team, but validation layers ensure changes are inspected before becoming the default.
These same security principles rely on defenses that prevent untrusted text from becoming high-risk actions, ensuring agents remain within their intended scope.
Managing Dependency and Tool Risks Within Agentic Pipelines
In coding pipelines, performing supply-chain checks in automation pipelines is essential to prevent trojaned dependency risks from quietly riding along with agentic workflows as teams scale their automation rules. A team may never notice the first bad pull if the agent keeps moving fast, which is why validation needs to cover tools and dependencies, not just the words in a skill file.
WildClawBench Evaluation: Measuring Performance in Real-World Friction
End-to-End Task Evaluation and Real-World Friction Testing
The SkillClaw paper reports significant performance improvements on WildClawBench, a benchmark designed to test agents under practical, end-to-end conditions rather than narrow lab puzzles. Researchers use a practical evaluation method to frame the goal of rewarding agents that can finish tasks without manual intervention.
How Operational Friction Impacts AI Agent Performance Metrics
By providing direct shell access and browsing capabilities, the evaluation environment forces agents to navigate the unpredictable layouts found in real work. In plain terms, it tries to reproduce the kind of friction that trips up automation in the real world, where a page layout shifts and the agent cannot rely on a clean, stable template.
Practical context is essential because traditional benchmarks often measure reasoning in isolation rather than real-world execution. Improving performance effectively requires more than just larger models; it demands a disciplined way to capture and distribute successful tool-use patterns across autonomous networks.

5 Practical Use Cases for Collective Skill Evolution in Automation
The benefits of shared updates are easiest to see in daily habits like build scripts or incident checklists. The list below is not a prediction market. It is a map of where reusable agent skills tend to create the most visible day-to-day impact.
- Developer Tools that Remember Fixes. Agents stop repeating broken steps by using permission-scoped tool catalogs to log every attempt and limit system access.
- Operations Playbooks that Improve Over Time. Procedures remain readable through markdown-based knowledge bases that allow incident response checklists to evolve.
- Cross-Device Personal Assistants. Scheduling and browsing patterns improve as trust boundaries for automation shape what gets delegated and what stays locked down.
- Safer Long-Running Automation. Shared learning combines with KV cache compression for long sessions to reduce brittle behavior.
- Clearer Separation Between Skills and Memory. Governance is improved by using persistent memory layers in workflows to separate action playbooks from historical data.
Reliability adds up over time. When skills improve across a team, fewer people waste time rediscovering the same workaround, and fewer workflows depend on one person remembering the “right” prompt. The tradeoff is governance. Shared updates should be inspectable and reversible, not silently shipped into production by default.

Scaling AI Agent Reliability through Shared Experience and Governance
Continuous refinement through shared experience offers a grounded path toward AI agent reliability. In environments where agents manage code, data, and digital tasks, small improvements compound quickly because the same autonomous workflows get reused.
Governance remains the critical factor as skills evolve collectively. Real reliability will likely come from pairing shared learning with guardrails that keep changes inspectable, reversible, and limited in scope. As agent societies drift toward scams and looped behavior when autonomy lacks oversight, the focus must stay on creating transparent update loops that ensure every shared skill remains a verified asset rather than a hidden risk.
Frequently Asked Questions About SkillClaw and AI Agent Skill Updates
What is collective skill evolution in AI agents?
Collective skill evolution is a process where AI agents improve by learning from interaction traces across multiple users, updating a shared repository so every instance of the agent benefits from individual successes.
How does SkillClaw improve autonomous workflow reliability?
The system captures session data through a client proxy and uses an evolver to turn repeated failure patterns into more reliable instructions, ensuring agents stop making the same operational mistakes.
What does WildClawBench test in the SkillClaw framework?
WildClawBench provides tool-based benchmarking that forces agents to handle real-world friction, such as shifting web layouts and incomplete information, inside a controlled OpenClaw framework environment.
Is it safe for agents to share skills system-wide?
Safety is managed through validation workers, approval gates, and sandboxed execution environments, which ensure that new skills are inspected and verified before they are deployed to other users.
How are AI agent skills different from model memory?
An agent skill is a reusable playbook for completing specific tasks, whereas memory stores specific session data; collective evolution focuses on refining the “how-to” playbooks rather than just recalling past events.
{kind=link}