Processing long-context LLM inputs forces a dramatic shift in computational priorities. As prompts expand into hundreds of thousands of tokens, the prefill latency becomes the dominant factor. Inference wait times are dictated by the preparation period, which establishes the time to first token (TTFT). This creates a significant cost and performance barrier for modern AI deployments.
Explaining these dynamics reveals why sparse attention struggled with hidden costs and how IndexCache stabilizes performance. Reusing token shortlists across adjacent layers reclaims significant speed while maintaining output integrity.
Engineers and decision-makers requiring grounded insights into latency, operational costs, and environmental footprints will find these explanations tailored for immediate application. Practical methods for token shortlisting lead to massive efficiency gains by targeting the inference bottleneck. Evaluating the inherent trade-offs in sparse attention clarifies why long-context preparation times dominate the current LLM landscape.

Key Performance Insights: IndexCache and Sparse Attention Benchmarks
- IndexCache reduces redundant indexer work by leveraging cross-layer token shortlist stability within indexer-based sparse attention frameworks.
- Benchmarks report up to 1.82x faster prefill and 1.48x faster decode in long-context tests, with results that depend on the chosen retention pattern.
- DeepSeek V3.2 makes the token shortlisting idea more concrete with a DeepSeek V3.2 sparse attention approach that frames why long prompts shift the bottleneck toward preparation time.
- Peak performance gains emerge when indexer operations constitute a substantial portion of prefill latency.
- Meaningful latency reduction occurs only when indexing work exceeds baseline rounding errors.
- High-volume context environments see the most dramatic efficiency shifts.

Fundamentals of Long-Context Inference: Managing Prefill and Decode Phases
The Long-Context Tax: Analyzing the Impact of High Token Volume on Latency
Analyzing extensive prior text requires balancing two critical inference phases: prefill and decode. Processing the input prompt occurs during prefill, established before any output generation begins. For very long prompts, prefill can dominate the total wait time, or time to the first token. Serving stacks often balance TTFT and throughput by configuring batched prefill token limits, which dictate the volume of prompt work processed simultaneously.
Metaphorical comparisons help clarify prefill mechanics for non-technical stakeholders:
- Skimming large files to locate specific quotes mimics the prefill scan.
- Increasing page counts naturally extends the scanning duration.
- Locating specific data points requires significant upfront effort before drafting begins.
One small team summarizing a lengthy court filing realized a single attentive read outlasted the actual drafting process. Persistent bottlenecks surface in long-context LLM workflows.
Current trends in sophisticated agentic AI orchestration and extended context window scaling force models to manage massive memory loads.
Escalating memory demands inevitably increase prefill times. For researchers and cloud providers, this translates directly into higher GPU expenses and operational overhead.
Prefill Versus Decode
Prefill is the initial pass that creates the key/value memory for the context. Decode is the token-by-token generation phase that follows. Optimizations reducing decode costs often fail to improve prefill. Since prefill runs once per request, its expense dominates operator bills for long prompts. Adopting physically separated prefill and decode tasks exposes these metrics clearly, making the prefill-decode distinction essential for evaluating optimization strategies in modern long-context systems.
Mechanics of Sparse Attention: Targeted Token Selection and Model Efficiency
Sparse attention techniques employ selective token attendance strategies to avoid computing attention scores over every possible pair of tokens. Instead of attending to every past token, the model shortlists a smaller set of tokens that are likely to matter and computes attention only for them. Concentrating efforts on a shortlist shrinks the heavy O(L^2) burden of naive attention toward a manageable O(Lk) scale.
Technical accessibility improves when complex AI concepts mirror everyday tasks. A practical analogy helps clarify how sparse attention handles massive datasets without exhausting resources:
- Scanning an index instead of every phone book entry identifies likely pages.
- Narrowing the search ensures the primary lookup remains computationally cheap.
- Rebuilding the index frequently introduces new time costs.
Stable indexing provides two primary architectural advantages:
- Logical consistency across layers reduces the need for constant re-ranking.
- Efficient reuse cycles prevent models from repeating redundant setup tasks.
A minimal anecdote: A product team once realized that saving and reusing a shortlist of likely interview questions cut their prep time in half. The same principle applies: reuse where stability exists and you avoid repeating the same setup work.

DeepSeek Sparse Attention (DSA) and the Indexer Bottleneck Challenge
Surgical Token Selection Using the DeepSeek Lightning Indexer
DeepSeek Sparse Attention is a concrete sparse-attention design documented for high-efficiency sparse-attention performance, employing a fast indexer to score preceding tokens and produce a top-k shortlist for each query. That shortlist is fed to the core attention operation, which now runs on k tokens rather than L tokens.
Lightweight indexer designs still require full-context inspection. These operations emulate O(L^2) complexity when executed across every layer, as each stage repeats ranking tasks for multiple query positions. Stability across adjacent layers allows for seamless index reuse, as confirmed by the latest experimental data.
What the Lightning Indexer Computes
The indexer computes a quick relevance score for every preceding token relative to each query token, then produces a fixed-size shortlist, often prioritizing the highest-scoring token candidates for the final attention calculation. Those candidates are where the heavy attention math runs. Core attention handles a smaller computational load, though the indexer still reads the full context to assemble the shortlist.
How Top-k Selection Feeds Core Attention
Once the top-k set is chosen, the attention calculation is exact or near-exact on that subset. That preserves much of the model’s capacity to reason while dramatically reducing the number of pairwise multiplications. The trade-off is that if the shortlist misses a crucial token, the downstream answers can degrade.
Quantifying the Hidden Tax: Repeated Indexer Scans in Multi-Layer Architectures
Sparse attention reduced the heavy lifting of full attention, but it did not eliminate prefill cost in all cases. The indexer step, the act of producing shortlists, can remain expensive if repeated across many layers. In technical terms, the system exchanges a single O(L^2) attention step for an O(N \cdot L^2) indexer pattern, provided the indexer runs across every one of the N layers.
Scaling L transforms the indexer’s full-context scans into a primary driver of end-to-end latency.
Long-agent conversations and massive documents highlight this inefficiency. Repeatedly rebuilding nearly identical shortlists consumes unnecessary resources without adding value.
Maximizing throughput requires a focused optimization strategy:
- Identify redundant ranking tasks that occur per-layer.
- Reuse previous results where token shortlists remain stable.
- Target the indexer bottleneck specifically during long-context prefilling.
Implementing IndexCache: Cross-Layer Reuse and Performance Metrics
Partitioning Full and Shared Layers for Optimized Index Reuse
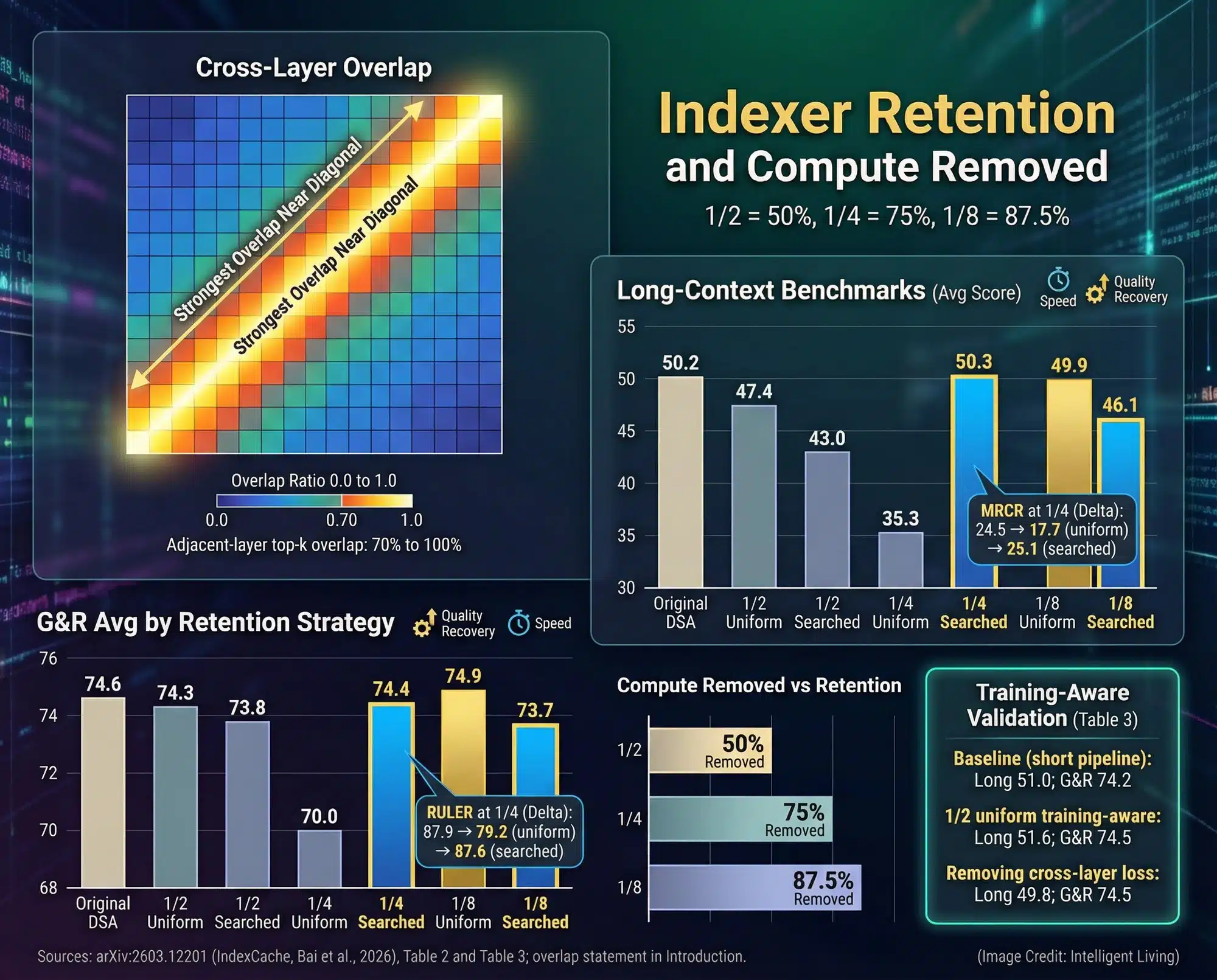
IndexCache addresses the hidden tax by observing that adjacent layers tend to pick largely overlapping top-k shortlists. Instead of running the indexer at every layer, IndexCache designates specific layers for index computation and allows subsequent layers to reuse those results. Strategic partitioning minimizes indexer runs without altering the core attention operations.
Implementers can choose between two deployment paths depending on specific latency goals. The training-free approach searches for a Full/Shared pattern that minimizes loss on a calibration set and can be applied to an already-trained model. The training-aware approach trains indexers with a multi-layer distillation objective so retained indexers better serve multiple layers’ needs.
The Cross-Layer Similarity Observation
Empirical analysis in the IndexCache paper shows high overlap between adjacent layers’ top-k lists, often with overlap ratios well above 0.7. That means a large portion of the shortlist is stable across neighbor layers, providing the statistical license to reuse the index.
Full Layers, Shared Layers, and Reuse Rules
A practical setup might compute indices every fourth layer and reuse them for the three layers following it. The paper explores different retention ratios and reports prefill and decode improvements under several conservative patterns. The exact pattern depends on model architecture, context length, and the acceptable accuracy trade-off.
Where Reuse Can Break (Early-Layer Sensitivity and Drift)
Index similarity is strongest between adjacent layers; similarity degrades at long separations and in parts of the model that handle very different representations. Early layers that encode raw token signals can be more sensitive, so aggressive reuse there risks missing early distinctions that propagate forward. For production use, the paper and the implementation recommend conservative retention strategies and, where possible, a small calibration set to validate any Full/Shared pattern.
Implementation Snapshot: The runtime idea is simple: keep a small cache buffer for the selected indices and choose, layer by layer, whether the indexer runs or the previous shortlist is reused. The important operational detail is that index reuse only helps when indexer work measurably contributes to time to the first token.
Empirical Benchmarks: Prefill Speedups and Quality Constraints
Prefill and Time-To-First-Token Gains
IndexCache delivers its most significant gains during the prefill phase. Controlled evaluations of prefill acceleration show up to 1.82× faster performance on 30B DSA models with long prompts. These results indicate the model generates answers nearly twice as fast under specific retention patterns.
Reducing prefill scans by even small percentages materially upgrades the user experience. Applications spending minutes on prompt processing gain the most from these latency cuts. Shaving prefill time by a third transformed weekly research cycles into daily ones for a team deploying long-document QA.
Decode Throughput Gains
IndexCache also improves decode throughput, though the relative gains there are smaller than prefill improvements in the authors’ results. Analyzing latency dynamics during concurrent request scheduling reveals how mixed prompt lengths and streaming outputs impact dominant metrics. Interactive systems prioritizing throughput and server-side concurrency find these decode gains essential for maintaining responsiveness.
Careful profiling is essential: some models and kernels (for example, fast attention kernels like FlashAttention) already squeeze strong per-token performance, so the wall-clock improvements from IndexCache can vary with low-level engine choices. View IndexCache not as a singular fix but as a lever that complements kernel optimizations.
Quality, Boundaries, and What Benchmarks Do Not Prove
Benchmarks show that, within the tested retention ratios and datasets, quality degradation was modest. However, benchmarks are controlled: they do not encompass every adversarial or agentic workload. Index reuse works because adjacent layers are often stable in their token shortlists. Where that stability vanishes, such as in early encoding layers, adversarially constructed prompts, or token-sensitive tasks, aggressive reuse will increase error risk.
The pragmatic takeaway: the reported numbers are compelling, but production teams must validate IndexCache on representative, in-the-wild data before adopting aggressive retention settings. The authors themselves recommend a calibration set and conservative initial patterns.

Long-Context Inference Basics: Prefill, Decode, and Sparse Attention
Comparison of Training-Free Search and Training-Aware Distillation Methods
IndexCache offers two operational paths for adoption: a low-friction, training-free search and a higher-effort, training-aware distillation.
Training-Free Greedy Search (Calibration First)
The training-free path searches for a Full/Shared layer pattern that minimizes loss on a calibration dataset drawn from your real workloads. Applying this method to pre-trained models offers immediate production gains without the overhead of retraining. Rapid deployment cycles and customizable retention patterns make the ‘patch’ approach particularly attractive to engineering teams.
Training-Aware Multi-Layer Distillation (Quality Insurance)
Training-aware approaches embed multi-layer reuse objectives directly into the training phase. By approximating target distributions, this method ensures retained indexers serve multiple layers effectively.
Retraining or fine-tuning produces robust indexer behavior. These efforts allow for aggressive retention patterns without incurring significant accuracy penalties.
A systems group that adopted training-aware distillation reported more graceful degradation when testing on diverse document types. The effort to retrain was non-trivial, but the resulting resilience justified the up-front cost for heavy production workloads.
Balancing Compute and Memory: IndexCache in the Inference Pipeline
IndexCache is primarily a compute-side optimization. It attacks repeated indexer computation rather than memory movement or KV-store size. Grasping these architectural distinctions ensures the successful composition of high-performance serving stacks.
Memory-Centric Methods (Paged Attention and KV Strategies)
Some long-context slowdowns are driven by KV cache growth and memory movement, so systems focus on minimizing fragmentation and unnecessary transfers. Utilizing virtual memory principles for KV cache management ensures high batch sizes remain sustainable under long sequences. On modern accelerator stacks, serving primitives like scheduling and paged attention often matter as much as raw chip counts.
Strategies employing predictive selection for memory traffic prioritize only the most critical data per step.
Compute-Centric Methods (IndexCache and Kernel Optimizations)
IndexCache sits on the compute side: by reusing indices, it reduces the number of ranking passes the model needs to perform. Kernel-level tools optimizing memory access patterns during attention reduce computational costs by controlling reads and writes at scale.
Complementary Rather than Exclusive
Realistic serving stacks achieve peak performance by layering optimization types:
- Compute strategies like IndexCache to reduce repeated ranking overhead.
- Memory strategies target KV cache growth and data movement bottlenecks.
- High-impact token retention policies balance recent inputs with historical context to maintain reasoning quality.

Operational Deployment Strategies for High-Performance Serving Stacks
Technical Integration Guide: vLLM and SGLang Engine Patches
The runtime patch for vLLM and SGLang maintains low overhead without extra GPU memory. Integrating quantized inference and mixed-precision execution allows IndexCache to deliver peak gains by isolating the prefill bottleneck. For teams evaluating the patch, the following checklist represents practical steps and compatibility checks.
Compatibility and Integration Checklist
Success with sparse attention requires a structured deployment strategy. Following this compatibility and integration checklist ensures your serving stack remains optimized for long-context tasks:
- Confirm your runtime stack supports indexer-based sparse attention like DeepSeek.
- Isolate prefill time metrics across indexer scans, core attention, and KV movement.
- Select a calibration set reflecting the most adversarial prompts in your workflow.
- Adopt conservative retention patterns while monitoring the quality delta.
Early parameter testing prevents unexpected latency spikes. Systematic validation further empowers teams to pursue aggressive optimization as model performance stabilizes.
Rollout and Safety Practices
Maintaining model integrity during architectural patches is a priority for production teams. These rollout and safety practices safeguard the user experience while reclaiming significant inference speed:
- Deploy patches behind feature flags with real-time telemetry.
- Maintain a non-reuse baseline fallback to handle unexpected token drift.
- Monitor token overlap degradation and early-layer sensitivity.
Automated alerts trigger if overlap ratios fall below safety thresholds. This proactive stance ensures that long-context documents remain accurate and reliable.
Code and Runtime Notes
Developers can access publicly available implementation logic to review index reuse strategies in common serving engines. This patch highlights cache buffer management and conditional indexer skipping.
Economic and Sustainability Impacts of Faster Long-Document Processing
IndexCache lowers the barrier to useful long-context interactive applications. In the same direction, adopting right-sized models for multimodal document processing makes high-quality intelligence viable on restrictive hardware footprints. Teams building legal summarizers, research assistants, or agentic automation that must process entire documents will see better responsiveness and lower infrastructure costs when prefill time is reduced. For newsrooms or researchers waiting minutes on a long-context summary, a 40% to 80% prefill reduction determines if a tool remains viable.
Restrictive hardware performance boundaries turn long-context latency into a hard usability limit on smaller devices. Shaving preparation time remains critical for maintaining fluid workflows under strict local constraints.
Sustainability benefits follow from reduced GPU minutes. When repeated indexer runs are eliminated at scale, the cumulative effect is fewer GPU-hours and less energy consumption, a dynamic reflected in the environmental strain caused by rising long-context traffic, affecting both energy and water footprints. These savings compound in fleets of inference servers as utilization rises.
Cooling constraints can be as limiting as compute, especially in hot or water-stressed regions where heat rejection becomes a planning problem as much as a software one. Optimized thermal management for inference clusters clarifies why shaving prefill time reduces more than just cloud expenditures.

Final Assessment: The Future of Efficient Long-Context LLM Inference
Implementation of optimizations like IndexCache demonstrates that latency reduction remains achievable without relying on exotic hardware upgrades. By targeting the redundant ranking work that plagues deep layers, teams can achieve faster responses while keeping infrastructure costs manageable. Reusing stable data while validating new inputs provides massive utility for document-heavy applications and complex agentic automation.
Efficiency is paramount as the costs associated with advanced compute infrastructure continue to escalate. Shifting the focus toward intelligent reuse rather than raw power allows for more sustainable data center operations and lower per-request billing. LLM inference optimization provides a more viable path forward than simply scaling up accelerators.
Common Questions About Sparse Attention and IndexCache
How does IndexCache reduce prefill latency?
It avoids the redundant ranking of tokens at every model layer. Reusing the indexer’s shortlist across adjacent layers cuts the total computational work required to process long prompts.
Is IndexCache compatible with all LLM architectures?
This specific optimization targets indexer-based sparse attention designs, such as DeepSeek Sparse Attention (DSA). Implementation relies on having a dedicated indexer step.
What is the primary difference between prefill and decode phases?
Prefill is the initial pass that processes the entire input prompt to build memory. Decode is the subsequent phase where the model generates new tokens one by one based on that context.
Does reusing indices across layers impact model accuracy?
Research indicates that adjacent layers often select nearly identical token shortlists. Reusing these indices results in minimal accuracy drift. This stability holds when teams apply conservative retention patterns alongside proper calibration.
Why is sparse attention critical for ultra-long context windows?
Standard attention scales poorly as the document length grows. Sparse attention allows the model to focus only on the most relevant tokens, making it possible to handle windows of 128k tokens or more efficiently.
{kind=link}