Scaling machine learning systems beyond certain limits shifts focus from model quality to environmental and operational constraints: memory pressure, latency spikes, and efficiency-first AI data center requirements regarding energy and water usage.
Infrastructure constraints regarding cooling and power availability explain why efficiency-first architectures are accelerating across the industry. Fourier features and frequency-domain reasoning are appearing in modern AI as a practical solution for these challenges. These techniques let models mix information globally using Fourier token mixing, surfacing structure that is hard to see in raw token space with far less overhead than quadratic self-attention.
Leveraging the Fast Fourier Transform (FFT) empowers engineering teams to replace expensive pairwise interactions with a high-speed spectral approach. Such transitions enable global information blending without traditional Transformer memory taxes, providing a critical lever for sustainable AI deployment.

Core Principles: Fourier Basics and the FNet Token Mixing Advantage
Key Takeaways: FNet Architecture and the Spectral Advantage
- FNet’s Core Idea: FNet’s core innovation, as established in the pioneering FNet encoder research, involves replacing quadratic self-attention with Fourier token mixing so the model can blend sequence information with lower compute and memory overhead.
- What “Frequency Advantage” Means: A Fourier transform, executed through an optimized Fast Fourier Transform algorithm, decomposes a sequence into frequency components so patterns that repeat, drift, or oscillate become explicit. Such spectral transformations enable global mixing that is cheaper than building a full token-by-token attention map.
- Architectural Tradeoffs: Replacing attention does not render it obsolete; rather, broad evaluations of efficient Transformer architectures highlight how production systems balance precision against speed, memory relief, and operational costs.
- Why It Matters Now: Dominant inference costs ensure that even minor efficiency gains compound, forcing architecture choices to reflect primary budget priorities.
Understanding Fourier Transforms in Neural Signal Processing
Spectral decomposition rewrites sequences as combinations of repeating patterns, a process intuitively similar to adjusting bass and treble on a sound system. This functional core of the Fourier transform allows models to identify and manipulate hidden structures within raw data.
One knob lifts slow, rolling waves, while another reveals fast, jittery texture. Sensory intuition confirms that mathematical structure is measurable and malleable, moving beyond the limitations of raw complex equations.
Architectural logic separates token streams into components that change slowly across the sequence and those that oscillate rapidly. Spectral mixing allows models to compare global patterns without explicitly scoring every token pair. This efficiency is driven by amplitude, which measures pattern strength, and phase, which indicates where that pattern aligns within the sequence.
FFT-based audio analysis demonstrates how structure is extracted from messy sound, providing a clear parallel for AI activation patterns. Spectral diagnostics reveal when models functioning correctly on short inputs begin to drift on longer sequences, providing a faster warning signal than traditional accuracy metrics.

Inside FNet: Fourier Token Mixing and Why it Works
FNet Architecture: Replacing Self-Attention with Fourier Mixing
Computational efficiency defines FNet’s reengineering of the standard Transformer stack. Spectral substitution of the traditional attention block with a token-mixing layer achieves global reach while avoiding quadratic scaling penalties.
Efficiency-first architecture maintains high performance through several spectral mechanisms:
- These replace the expensive pairwise interaction step characteristic of the standard Transformer self-attention mechanism.
- Feedforward Stability: The encoder continues to rely on feedforward networks and residual connections for depth.
- Static Mixing: The fixed nature of the transform ensures most learning occurs within the feedforward layers.
Strategic structural parameters shape the mixed representation, maintaining a lightweight profile while ensuring peak model performance.
Token Mixing Versus Attention
Self-attention establishes quadratic pairwise affinities to compute token relationships, creating significant computational overhead. Quadratic scaling ensures that granularity grows alongside sequence length, creating a significant memory and bandwidth tax for production environments.
Frequency-based token mixing utilizes a global transform to blend tokens according to specific patterns. This method trades token-to-token explicitness for significant compute savings, proving highly effective for classification, ranking, and retrieval workloads. Spectral blending serves as a high-speed semantic processor, particularly for tasks prioritizing overall contextual meaning over granular token-to-token alignment.
The Fourier Mixing Step Explained
FNet treats token embeddings as sequence signals by applying a discrete Fourier transform to the token-by-feature matrix. Resulting spectral outputs represent the frequency domain, which the model maps back into token space via the real component before processing through standard feedforward layers.
Technical specifications for the FNet model outline training assumptions such as the absence of attention masks and a Fourier layer that returns only the real part. Overlooking these constraints causes exactly the kind of mismatch that triggers silent quality drops.
When FNet is a Better Fit
FNet is most attractive in encoder-heavy pipelines where latency, memory, or cost are hard constraints. Semantic search and embedding workflows are common candidates because they often need throughput more than token-by-token interpretability.
Memory-intensive workloads pushing against the KV cache memory wall benefit most from architectural levers that reduce data movement. Deployment teams optimizing retrieval systems recognize that saving milliseconds on embedding throughput ensures stable concurrency and prevents accumulating queues.
Why this Works: Fourier as a General ML Unlock
Frequency-domain methods are not a one-off trick. They sit inside a broader pattern in machine learning where changing the representation can make the same network class learn harder functions. A superior mathematical basis exposes buried structure, allowing networks to learn complex functions more effectively.
Spectral Bias in Plain Terms
Neural networks prioritize smooth, low-frequency structure during early learning phases, often delaying or omitting the capture of fine-grained oscillations. This spectral bias pattern ensures optimization favors global shapes over the sharp details that typically arrive in later training stages.
High representation accuracy on global curve shapes often masks missing jagged edges that define true precision. That mismatch shows up in real products when a model gets the gist right but fails on the one constraint that actually matters.
Fourier Feature Mappings and Practical Effects
The Fourier feature mapping approach by Tancik and colleagues shows how sinusoidal feature mappings help networks represent high-frequency structure more effectively. In plain terms, a better basis makes certain patterns easier to express.
That is the bigger reason Fourier keeps appearing in modern AI. It can turn hidden structure into a form the model can mix or preserve efficiently.
The idea also has older roots. A random Fourier feature method showed that frequency-based mappings could scale certain kernel-style representations, reinforcing that frequency space is not just a math classroom detour.
A final bridge back to infrastructure helps the story feel real. In modern networking and compute design, photonic data center interconnects are engineered around wave behavior because power and bandwidth limits force more efficient ways to move and transform information.

Performance Validation: FNet Benchmarks and Spectral Mechanisms
What FNet Delivers in Practice: Speed, Scaling, and the Real Tradeoffs
Strategic objectives for FNet deployment include reducing memory and compute friction during sequence processing. Engineering teams often accept minor accuracy tradeoffs to secure superior throughput and cost efficiency.
Reported Results and How to Read Them
Baseline evaluations measured FNet performance across the standard GLUE benchmark tasks, confirming that Fourier mixing retains encoder utility while outperforming attention in speed. The most defensible data appears in the published FNet performance findings, and these metrics should be treated as outcomes under those settings, not guarantees for every dataset.
For long-input behavior, the Long Range Arena efficiency evaluation provides critical context for models operating under high-memory conditions where efficiency methods can diverge. Long-context metrics better address production-critical concerns regarding system stability and speed during extended sequence processing.
Here is a blunt way to read the benchmark story. If your failures come from memory and latency, an efficient encoder that is slightly less precise can still produce a better user experience than a slower model that cannot meet the budget.
Memory, Latency, and Cost Considerations
Attention overhead scales poorly by creating and manipulating massive intermediate structures. Fourier token mixing eliminates the need for these pairwise maps. Reducing this requirement lowers memory pressure and effectively relieves critical system bottlenecks.
For teams that run large workloads, the most convincing argument is not abstract complexity. It is a measurable cost. A team optimizing a production embedding service often discovers that a small drop in per-request memory can raise concurrency enough to change infrastructure costs across the month.
If your use case still needs attention, it helps to understand why modern stacks invest heavily in sparse attention caching tricks rather than treating attention as free. Even modest reductions in bandwidth and cache churn can matter more than raw FLOPs when systems run hot.
Mechanistic Insights: Fourier Features in Pretrained LLM Arithmetic
Internal model mechanisms reveal that Fourier features act as more than external tools; they represent learned primitives within pretrained architectures. That split between visible behavior and internal mechanism sits at the center of the predictive illusion of thought in LLMs, specifically when models sound confident but fail on precise structure.
Mechanistic analysis of LLM arithmetic reasoning suggests that pretrained models utilize frequency-sparse components to represent numeric data. Theoretical frameworks suggest internal features behave like a compact frequency basis rather than literal FFT routines during inference.
What Frequency-Sparse Features Look Like
Pretrained models utilize specific hidden-state trajectories to concentrate energy at distinct frequency bands. This modular organization simplifies how numeric signals are processed.
The model distinguishes between two primary frequency types:
- Low-Frequency Components: These signals align with magnitude, representing the slow-moving portions of a numeric value.
- High-Frequency Components: These capture modular properties such as parity, carries, and wraparound behavior.
Spectral primitives enable later layers to combine information without relearning the entire representational foundation.
Roles of Different Layers
Mechanistic analysis reveals a distinct division of labor within the architecture. Feedforward layers prioritize low-frequency signals for approximate magnitude, while attention-like pathways leverage high-frequency signals to handle modular properties.
Modular carries exemplify this frequency split, functioning as threshold events rather than smooth transitions. These sharp patterns require high-frequency capacity for clean representational accuracy.
Their broader implication is useful even if you never build an arithmetic model. Pretraining can create representational primitives that later make specialized tasks easier, not because the model memorized answers, but because it learned a compact basis for structure.

How to Use This in Development (Teams and Solo Builders)
Think of this as a set of small, low-risk experiments that give you real numbers fast. The goal is to measure whether Fourier token mixing improves latency and cost without quietly breaking the quality your users notice.
Pilot Plan for Engineering Teams
- Bundle production success metrics to acknowledge that user experience and operational expenses are fundamentally inseparable.
- Build a Baseline: Run the attention encoder on representative workloads and measure end-to-end latency, memory usage, and cost under realistic traffic profiles, including efficient KV-cache scheduling tradeoffs as context grows.
- Run a Controlled Swap: Introduce Fourier mixing in staging, then compare throughput and output quality under identical workloads.
- Measure Across Conditions: Observe cold-start behavior, batch-size sensitivity, and the shape of tail latency.
Solo Engineer Roadmap
- Prototype on a Small Encoder Task: Fine-tune an FNet-style encoder on a classification task to learn the behavior of Fourier token mixing in practice.
- Add Frequency Diagnostics: Sample hidden activations and compute FFT amplitude summaries across the token dimension to monitor drift, utilizing standard FFT implementation guidance as a sanity check for your pipeline.
- Efficiency gains that appear minor in isolation become highly meaningful when scaled across production environments.
Add a Lightweight Hallucination Tripwire
Frequency tools can also be a reliability layer. The HSAD method for spectral hallucination detection treats activation signals as temporal sequences, maps them into frequency space, and extracts spectral features that correlate with hallucination risk.
This is not a replacement for evidence and verification. It is a fast warning signal that can tell you when a system is drifting into confident nonsense.
For workflows that require stronger auditability, iterative verification with deep research agents illustrates a pattern that reduces single-pass overconfidence.
Adoption Listicle: Ten Practical Steps
- Swap Fourier mixing into a staging encoder for classification or retrieval workloads.
- Prototype a hybrid design that keeps attention where fine-grained dependency matters.
- Add a spectral drift check using FFT summaries over hidden activations.
- Track latency distribution, not just average latency.
- Convert throughput and memory wins into budget language using carbon-aware FinOps and GreenOps strategies that make efficiency measurable.
- Create a rollback runbook before you deploy any architectural shift.
- Add a hallucination tripwire and log it like a first-class metric.
- If you generate or review code, treat hallucination as an engineering defect, and use AI coding risk frameworks to set expectations.
- Tie deployment choices to numeric efficiency by tracking FP8 efficiency tradeoffs that affect bandwidth, memory, and cost.
- Document the experiment as a template so the next model transition is faster and less political.
Teams that move fastest usually do the boring part well: they treat latency, memory, and quality checks as daily instrumentation, not a heroic cleanup after something breaks.
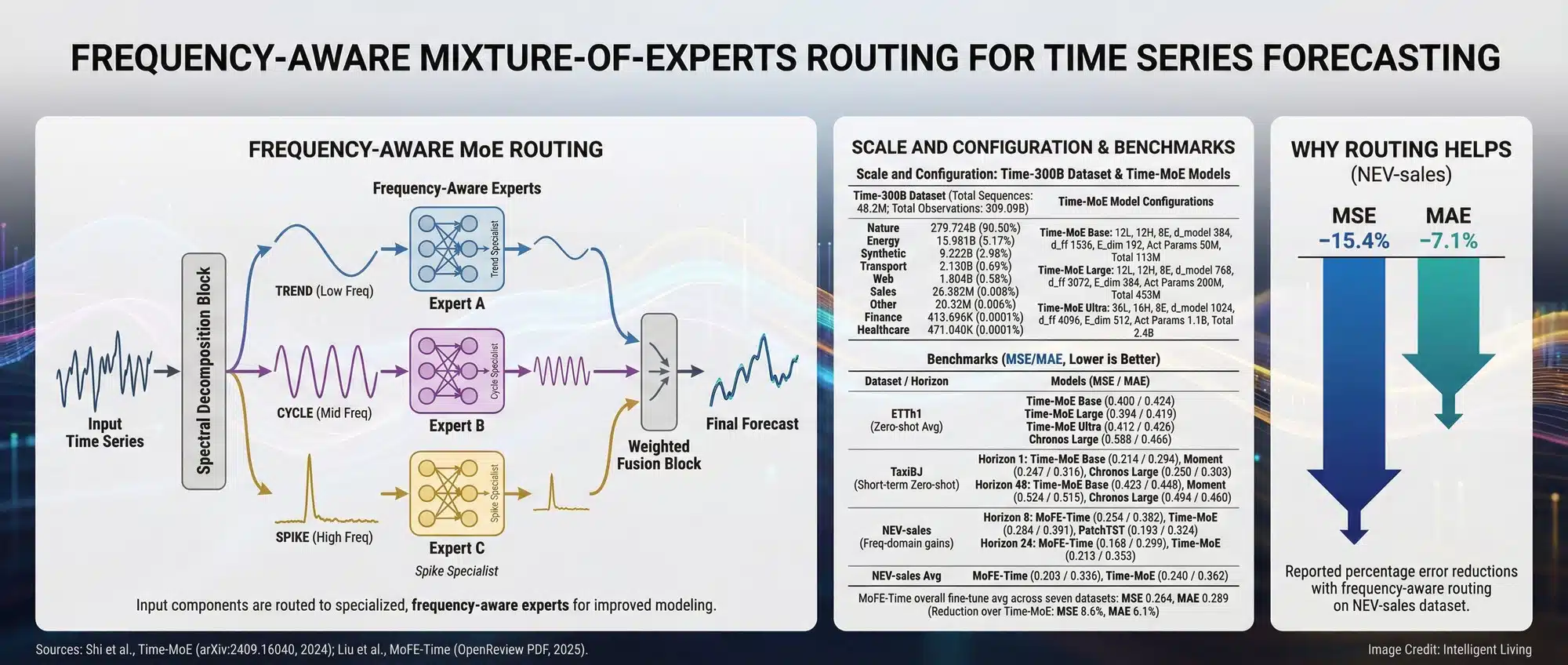
Adapting MoE for Time Series with Frequency-Aware Experts
The FM-LLM framework for forecasting with frequency-aware MoE leverages a mixture-of-experts approach to handle complex seasonality while keeping the large language backbone largely stable. Time series data carries seasonality, cycles, and abrupt shocks that become clearer through spectral decomposition rather than raw time-domain values. It also hints at a practical path for teams that want forecasting gains without retraining an entire foundation model.
Why Time Series Invites Frequency Thinking
Time series data naturally decomposes into distinct frequency bands. Cycles, seasonality, and anomalies are significantly easier to isolate in frequency space than in the raw time domain.
In production environments, this separation simplifies feature engineering. Teams can track a handful of dominant bands rather than chasing every minor oscillation in the raw data curve.
A practical bridge is that modern LLM systems already borrow MoE strategies for efficiency. The idea is visible in MoE deployment patterns in GLM-5, where only a subset of parameters activates per request to manage cost and speed.
Strategic MoE Routing for Frequency Expert Specialization
Frequency-enhanced experts specialize according to spectral characteristics:
- Trend Experts: Focus on slow-moving components.
- Cycle Experts: Monitor mid-band seasonal patterns.
- Anomaly Experts: React to sharp spikes critical for detection.
Spectral separation prevents common forecasting failures caused by confusing seasonal fluctuations with fundamental regime changes.
A practical way to evaluate the idea is to compare error behavior, not just average error. Watch whether the model improves on peaks, turning points, and sudden shifts, because those are the moments that usually trigger downstream decisions.

Scaling Efficiency with Fourier Token Mixing and Spectral Reasoning
Frequency thinking has shifted from a math curiosity to an essential engineering lever for modern AI stacks. FNet demonstrates how a conceptually simple change to Fourier token mixing can drastically shift infrastructure economics, while mechanistic research hints that pretrained models already carry Fourier features as representational primitives.
Operational habits for engineering teams prioritize piloting. Fourier-mixed encoders on low-risk pipelines while integrating spectral drift signals. Next-generation deployment focus shifts from raw FLOPs to the bandwidth and cache efficiency essential for sustainable AI.
Adopting a frequency-first lens ensures your models remain performant and sustainable under production load. If your stack is moving toward local inference, comparing local AI versus cloud carbon footprints clarifies the real-world impact of these efficiency gains.
Expert FAQ: FNet, Fourier Features, and LLM Efficiency
How does FNet replace attention for faster token mixing?
FNet swaps the standard quadratic self-attention block for a discrete Fourier transform layer. This allows the model to mix all tokens simultaneously across the sequence using frequency components, significantly reducing compute and memory overhead compared to pairwise maps.
What are the main benefits of using Fourier features in AI?
Fourier features allow neural networks to represent high-frequency structure and fine-grained patterns more effectively. This improves a model’s ability to learn complex functions and high-dimensional data, which is essential for tasks like image synthesis and arithmetic reasoning in LLMs.
Is Fourier token mixing as accurate as self-attention?
While Fourier mixing is significantly faster and more memory-efficient, it can trade a small amount of precision in tasks requiring extreme token-to-token specificity. It is most effective for encoder-heavy workloads like classification, ranking, and retrieval-augmented generation (RAG).
Can I use frequency-aware MoE for time series forecasting?
Yes. A frequency-aware MoE framework allows different experts to specialize in specific frequency bands (like seasonality or trends). This helps the model separate cycles from abrupt shocks more clearly than raw time-domain processing.
How do Fourier features help detect AI hallucinations?
Spectral features extracted from hidden-layer signals can correlate with hallucination risk. By mapping activation trajectories into frequency space, teams can create a “hallucination tripwire” that flags when a model’s output begins to drift into confident but structurally inconsistent nonsense.
{kind=link}