China recently unveiled a fully domestic exascale-class supercomputer in Shenzhen, making a bold claim: over 2 exaFLOPS of sustained scientific performance achieved without foreign accelerators. This system, known officially as 灵晟 (LineShine), represents a massive leap for the nation’s homegrown computing stack architecture, aligning with the broader push for domestic silicon independence. Tracking the sudden collision of AI chip shortages, tightening export controls, and unprecedented electricity demand reveals why Shenzhen’s latest breakthrough sits at the absolute epicenter of these global pressures.
You might wonder how a system can reach such speeds without traditional GPUs. The strategy focuses on compute sovereignty, ensuring that critical AI infrastructure remains resilient even when international supply chains shift. By prioritizing a domestic hardware ladder, this project aims to provide a stable platform for massive parallel math and industrial simulations that previously relied on imported silicon.
Advanced computing is no longer just a technical niche; it is behaving more like vital energy infrastructure. This shift is visible in everything from national grid planning to recent commitments to power AI data centers, framing energy-intensive compute growth as a tangible real-world cost. As we analyze the LineShine CPU architecture, it becomes clear that the goal is to balance raw power with sustainable, self-controlled growth.

Decoding the LineShine Breakthrough: Key Specs of Shenzhen’s Domestic Computing Stack
LineShine Supercomputer Quick Facts: China’s 2 ExaFLOPS CPU-Only System at a Glance
LineShine has rapidly become the dominant nickname in English-language trade press for Shenzhen’s 灵晟 exascale project. The core engineering claim involves reaching a rare performance tier using a domestic hardware ladder that eliminates dependence on foreign accelerators.
If you are looking for a fast technical baseline before diving into the architecture, these quick facts separate official government briefings from outside industry reporting. Understanding these core details helps clarify why this CPU-centric design is such a strategic pivot for China’s high-performance computing (HPC) ecosystem.
Navigating the technical specifications of a system this large requires a look at its fundamental building blocks. These reported details highlight how the National Supercomputing Center in Shenzhen (NSCC‐SZ) is positioning its latest asset:
- Name variants: LineShine, Lingshen, and the Chinese name “灵晟” (pronounced Língshèng, meaning “Intelligent Splendor” or “Intelligent Brightness”).
- Announced in Shenzhen during a public event in April 2026, the project serves as a cornerstone of the latest regional high-performance computing disclosure.
- Marketed as a domestic computing stack, spanning processors, storage, and networking.
- Reported target of over 2 exaFLOPS sustained FP64 performance.
- Described in trade coverage as a CPU-centric or CPU-only exascale design.
- Positioned for scientific computing, AI model training, and industrial simulations.
By reviewing these stats, you can see that the focus is on a fully integrated domestic stack rather than a hybrid system. This shift away from imported silicon marks a significant change in how modern exascale architectures are being planned and deployed.

What Exactly Did Shenzhen Announce, and Who’s Behind It?
NSCC-SZ Project Scope: Tracking Official Performance and Design Claims
Officials at the National Supercomputing Center in Shenzhen recently presented this system as a breakthrough in compute sovereignty, emphasizing total control over the hardware stack from node to interconnect.
This pivot stems from strategic necessity. As international trade barriers limit access to advanced chips, the capacity to engineer and maintain a self-controlled computing platform emerges as a vital national security asset.
How Big is LineShine Supposed to Be?
Coverage differs on specifics, but the widely repeated scale claim involves a buildout of around 47,000 domestically produced CPUs. This figure should be treated as a reported project detail until verified through a formal benchmark or detailed technical disclosure.
At this scale, the system functions as more than just a single machine. It represents an engineered ecosystem of cabinets, networking, and cooling systems precisely synchronized to behave like one coordinated unit.
Why Networking Becomes the Quiet Bottleneck
Recent technical analysis of the project reveals a plan involving tens of thousands of CPUs linked by a custom networking fabric and high-concurrency fabric designed to minimize latency. Rapid data movement between nodes is the primary constraint at this scale, as high concurrency means even minor latencies can stall the entire system.
Operators are increasingly turning to innovations like photonic chips for data center networking to solve this. These links aim to deliver higher bandwidth while significantly reducing the energy required per bit of data moved.
If you picture a “supercomputer” as a single giant machine, it helps to reset that image. Modern exascale systems are clusters of interconnected servers. Think of rows of cabinets that look like industrial refrigerators, each packed with processors, memory, networking hardware, and cooling loops, all tuned so thousands of nodes do not drift out of sync.

The Exascale Standard: Analyzing FP64 Accuracy and the CPU-Only Architecture Bet
Understanding Exaflops and FP64: The Metrics of Scientific-Grade Accuracy
Exaflops in Plain Language
An exaflop means a quintillion calculations per second, using floating-point math that computers rely on for simulations, physics models, and large-scale data analysis. Official standards for sustained exascale performance thresholds require a specific level of reliability, moving beyond simple burst-speed demonstrations.
FP64 and Scientific-Grade Accuracy
FP64 is short for 64-bit floating point, often called double precision. It matters because it signals scientific-grade accuracy. When researchers model climate systems or simulate molecular interactions, small numerical errors can snowball into wrong results, especially when calculations stack for days.
Why “Sustained” Matters More than a Peak Number
Picture a laptop that runs smoothly for ten minutes before stuttering due to restricted airflow and mounting heat—exascale systems must overcome this exact bottleneck at a quintillion-fold scale. Exascale systems are designed for the opposite problem: running hard calculations for long stretches without collapsing under heat, memory bottlenecks, or network delays. That is why “sustained” performance is the detail that separates a headline from a system that can carry real science and engineering workloads.

The Unusual Bet: How a CPU-Centric Exascale Design Differs from GPU-Heavy Leaders
Why GPUs Usually Lead Exascale Rankings
Global exascale leaders typically lean on specialized accelerators, particularly GPUs, to handle the massive parallel math required for modern AI. You can see this reflected in the standardized metrics used to compare exascale systems, where machines like El Capitan serve as the primary reference points for verified, benchmarked performance.
GPUs excel at running many calculations at the same time, which is why they are so effective for AI training and certain scientific workloads. Technical literature has long emphasized this efficiency gap, specifically identifying GPU performance-per-watt patterns as the deciding factor for high-concurrency parallel computing tasks.
What a CPU-Centric Exascale System Trades Off
The LineShine strategy diverges from this trend by utilizing a CPU-heavy build approach, which prioritizes domestic scaling over imported acceleration hardware. That choice can be read as an engineering strategy and a policy strategy at the same time, because the hardware mix is shaped by what is available, not only by what is ideal.
It can help to picture two construction crews. One relies on specialized equipment that is world-class but imported. The other builds with equipment it can reliably source and control. Both can put up tall buildings, but the second crew is planning around the risk of a work stoppage if shipments get delayed.
Why this Still Matters for AI Workloads
Even in a CPU-centric design, AI does not disappear. It shifts. Some tasks run on CPUs directly, some rely on software optimization, and some are limited by memory bandwidth and interconnect speed rather than raw compute. That is one reason the “CPU-only” headline can be misleading: the real question is whether the overall system can deliver fast, stable throughput for the mix of science and AI workloads it is being built to support.
Strategic Impact: How Compute Sovereignty Collides with Data Center Energy Limits
National Security and Supply Chain Resilience: The Role of Export Controls
What Export Controls Change in Practice
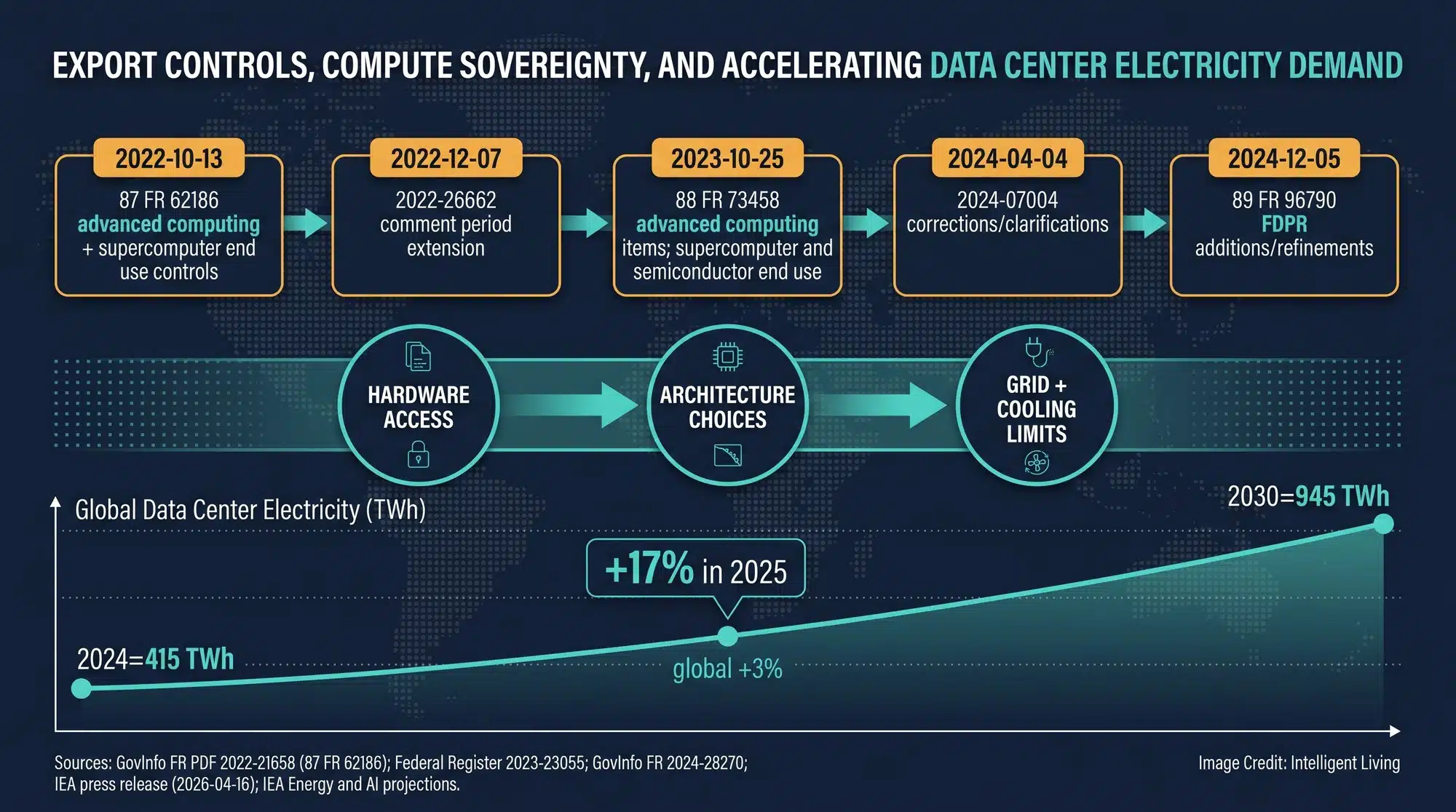
Compute sovereignty is the ability to build and operate advanced computing systems without being dependent on external suppliers for the most critical components. The U.S. Commerce Department’s Bureau of Industry and Security maintains a running hub of advanced computing export control updates, and the formal language behind those changes appears in the October 2023 export-control rule text. Together, those rules shape what hardware can be purchased, at what performance levels, and under what conditions.
Why Domestic Stacks Can Be Slower but Safer
Uncertain access to cutting-edge hardware forces nations to prioritize supply chain resilience through domestic alternatives. This strategy prioritizes operational continuity over raw peak speeds, especially as limits on advanced chip production shipments force a re-evaluation of long-term hardware availability. Treating compute as strategic infrastructure rather than a global commodity ensures that vital research isn’t derailed by trade shifts.
Where You See this Outside Government
This engineering logic even reaches the personal level, where users weigh cloud dependence against a local mini AI supercomputer hardware ladder to maintain workflow continuity without remote data centers. For everyday life, the impact is less abstract than it sounds: if AI services, scientific research, and industrial modeling depend on hardware that can be cut off or delayed, progress becomes less predictable.

The Part You’ll Actually Feel: Power, Cooling, Water, and the Cost of “Invisible Cloud” Compute
Electricity Demand is the New Constraint
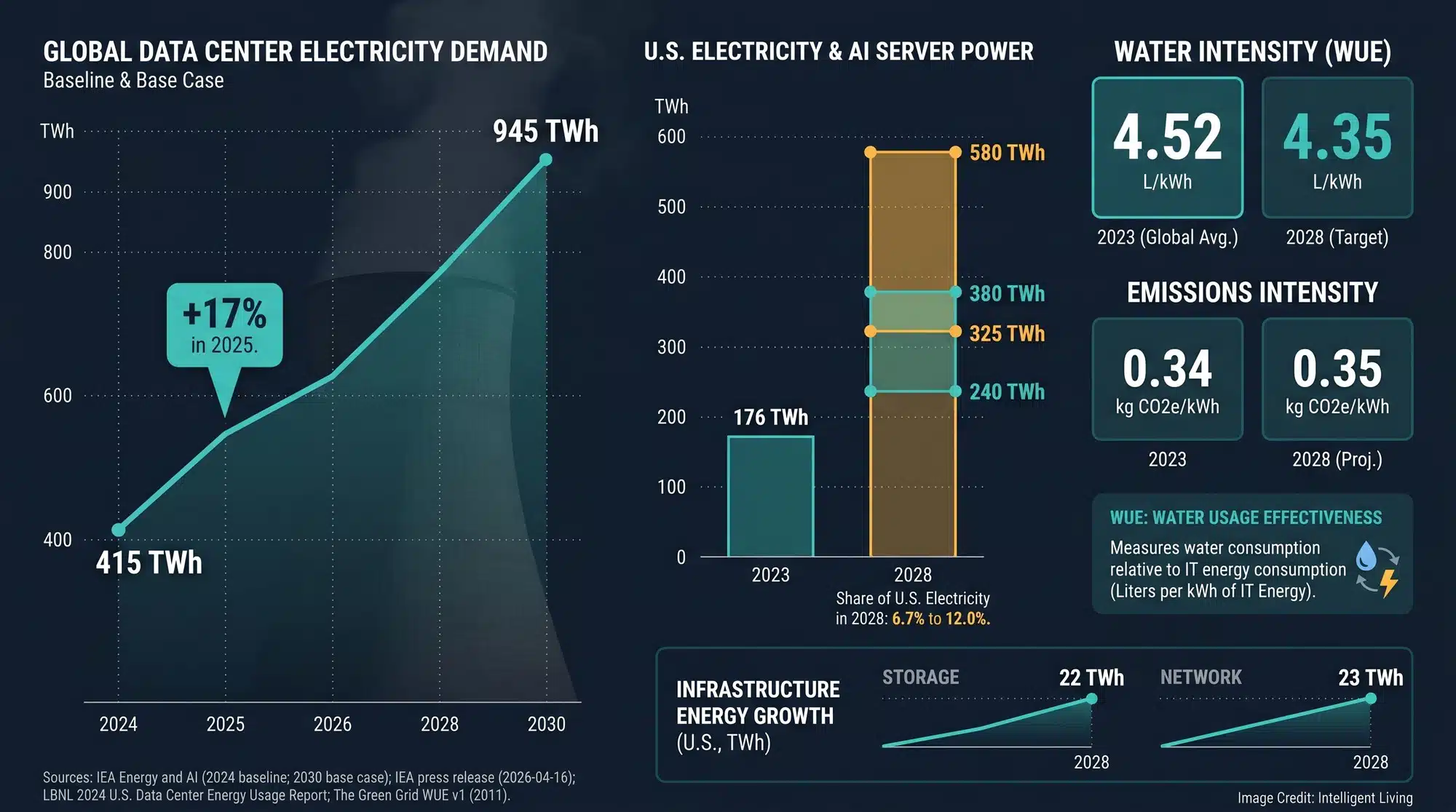
Next-generation supercomputers consume far more than just silicon; they require extraordinary levels of electricity that generate massive heat. Recent global data center electricity consumption baselines suggest a 2024 total of roughly 415 terawatt-hours, a number that scales directly with AI model complexity.
Analysts noted that surging data center electricity use in 2025 had already triggered a global scramble for grid solutions. As utilities race to keep up, bottleneck management has become as critical to progress as the chips themselves.
Detailed analysis of data center electricity demand outcomes could lead to several different energy outcomes through 2028, highlighting why forecasts vary based on the speed of AI integration. The underlying U.S. Data Center Energy Usage Report PDF shows why forecasts split so sharply when AI server growth accelerates.
Better measurement is becoming part of the story. The U.S. Energy Information Administration has announced a pilot effort described in its data center energy survey release aimed at understanding what these facilities actually consume, including the cooling systems that many people forget exist until a heat wave hits.
Cooling and Water are Part of the Bill
Power density serves as a hard ceiling for high-tier computing. Many exascale systems now hit a 10-megawatt wall in heat management, where the physical capacity to cool the hardware limits growth more than the number of chips in a rack.
This constraint has moved technical metrics like PUE (Power Usage Effectiveness) and WUE (Water Usage Effectiveness) into the mainstream. These terms serve as vital shorthand for measuring how efficiently a facility converts raw electricity and local water into computational power.
Why Location Matters More than People Expect
A new data hall built near a growing suburb does not feel like “cloud infrastructure” when the local utility starts planning upgrades and the community starts asking what happens during peak demand weeks. For households, the concern often lands as a blunt question about whether electric-bill pressure from data centers grows as more compute moves from novelty to daily habit.
Geography now dictates cooling efficiency, as some operators deploy infrastructure in extreme locations where ambient temperatures reduce the reliance on expensive, high-density air conditioning. That is the same constraint exascale builders face, just at a different scale.

Real-World Uses and the Verification Checklist
What this Kind of Supercomputer Gets Used For and Why it’s Not Just AI
High-profile AI training cycles often dominate the headlines, yet these supercomputers provide the essential power for a vast array of scientific workloads. Official plans for the LineShine project prioritize remote sensing, advanced materials science, weather modeling, and industrial simulations.
Data from exascale application development summaries shows that fields like biology and climate science only truly scale up when a system is optimized for sustained performance. This design philosophy prioritizes long-term reliability over short-lived technical demonstrations.
Exascale performance fundamentally changes materials discovery by enabling ultra-large atomistic simulation models that transform traditional trial-and-error research into a data-driven, measurable process. This allows for a 4-billion-atom exascale materials simulation to move from the realm of theory into a tangible, predictive engineering tool with implications for infrastructure durability and emissions.
AI training is part of the picture, but so is drug discovery, climate modeling, and electromagnetic simulation. If you have ever relied on improved weather forecasts or benefited from better battery chemistry, you have already seen the downstream value of high-performance computing. Exascale mainly changes the speed and scale at which those questions can be asked.
Performance Verification: Benchmarking Claims Against Global Industry Standards
Performance claims at this scale are typically validated through public benchmarks. Performance benchmarks for the Top500 list rely on Linpack standard measurements, which differentiate between theoretical peak speeds and the sustained output required for real-world science.
LineShine’s reported 2+ exaFLOPS sustained figure has not been accompanied by a publicly submitted Top500 HPL result at the time of writing. That does not invalidate the project itself, but it does mean performance should be treated as an attributed claim unless independently benchmarked. In practice, public ranking usually requires installed systems and data submitted through the Top500 submission schedule before results can be compared on the same terms.
Energy efficiency is also part of the verification conversation. The Green500 performance-per-watt rankings track which systems deliver the most output per watt, a metric that becomes more important as power constraints tighten.

The Impact List: How this Could Reshape AI and Science Over the Next Few Years
- Expanded domestic AI training capacity within China’s borders, reducing dependence on overseas accelerator supply.
- Faster scientific simulation cycles in materials, climate, and biomedical research, which can compress years of work into shorter iterations.
- Stronger pressure to treat data centers as heavy industry, with utilities planning upgrades as demand becomes measurable.
- A bigger push for efficient packaging and supply chain throughput, where the limiting factor becomes manufacturing capacity as much as chip design, including CoWoS chiplets and packaging bottlenecks that can slow even well-funded AI buildouts.
- More investment in cooling innovation and heat management, including liquid systems, as the energy wall becomes unavoidable.
- More fragmented global ecosystems, as nations optimize for their own hardware stacks and software toolchains.
- A more public debate about sustainability, as communities connect AI growth to electricity bills, water use, and grid stability, with interest growing around efficiency-first AI that cuts energy and water strain as operators chase more compute per kilowatt.
Success in this new era isn’t defined by leaderboard rankings but by how rapidly nations can redesign their AI infrastructure to ensure computational availability amid shifting trade and supply chain norms.

The Future of Global AI Infrastructure: Why LineShine and Compute Sovereignty Matter
LineShine represents more than a technical milestone; it signals a fundamental shift in how nations view high-performance computing. We are entering an era where compute is treated as an energy-linked strategic asset—as essential as oil or electricity—rather than a niche research tool. This pattern is accelerating globally as chip packaging constraints, data center power bottlenecks, and materials limits collide, a reality explored in depth through AI chip design agents and data center power limits.
The coming decade serves as a testing ground for whether CPU-centric architectures can breach the ’10-megawatt wall’ of power consumption. Consequently, the pace of scientific discovery now hinges on our ability to manage the massive, often invisible environmental and energy costs of the global cloud.
LineShine FAQ: Understanding Exascale, CPU-Only Chips, and Power Use
How Fast is the LineShine Supercomputer, and Does it Use GPUs?
LineShine targets over 2 exaFLOPS (two quintillion calculations per second) using a CPU-only design. Unlike most exascale machines that rely on GPUs for parallel math, this system uses a domestic computing stack to achieve high performance without foreign accelerators.
What is Compute Sovereignty and Why Does it Matter?
Compute sovereignty is the ability of a country to build and operate advanced AI infrastructure without relying on external suppliers or restricted technologies. It ensures that scientific research and industrial modeling can continue even if global trade rules or supply chains shift.
Why Are Exascale Computers Moving Toward CPU-Only Designs?
While GPUs are often more efficient for specific AI tasks, CPU-centric designs like LineShine prioritize independence and flexibility. This approach allows builders to optimize for available hardware while still supporting complex simulations and large-scale data analysis.
How Much Electricity Do these Supercomputers Actually Consume?
Modern exascale systems face a ’10-megawatt wall,’ requiring massive amounts of power for both calculation and cooling. Globally, data center electricity use is surging, leading many operators to scramble for sustainable data center energy solutions to keep costs and grid strain under control.
Can I Verify the LineShine 2 ExaFLOP Performance Claim?
Currently, the 2+ exaFLOPS figure is an attributed claim. Official verification typically requires a public submission to the Top500 list using the Linpack benchmark. Watch for future deployment milestones and energy efficiency disclosures to assess its real-world impact.
{kind=link}